Approcci moderni per la Generazione di Immagini (Text-to-Image & Video)
La generazione automatica di immagini e video tramite Intelligenza Artificiale si basa oggi su tre grandi famiglie di tecniche. Conoscere queste architetture permette di capire perché strumenti come Stable Diffusion, Midjourney, DALL·E 3 o Runway producono risultati diversi, con punti di forza e limiti specifici.
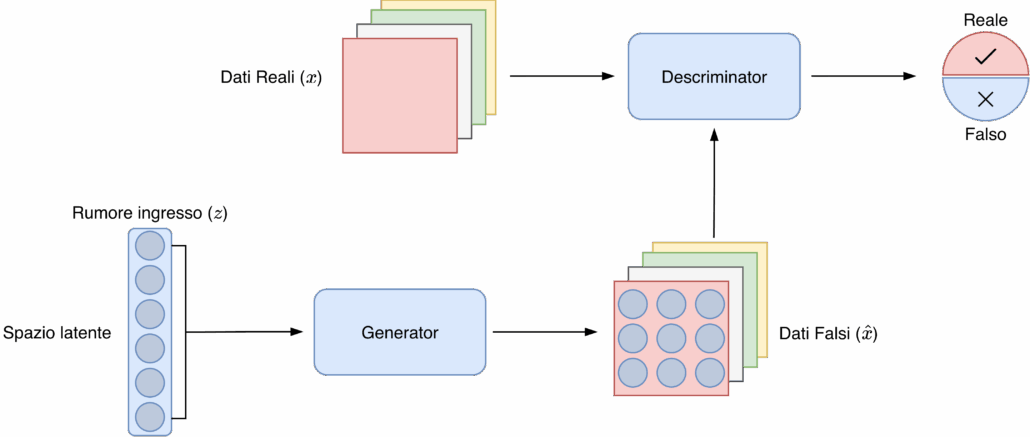
GANs (Generative Adversarial Networks)
Le GANs utilizzano due reti neurali che si sfidano tra loro:
- Un generatore che crea immagini a partire dal rumore.
- Un discriminatore che deve distinguere il reale dal generato.
Le GANs sono molto forti nella generazione di immagini fotorealistiche e producono risultati rapidamente. Sono particolarmente efficaci nella costruzione di volti, texture e scene ben definite. Tuttavia, offrono un controllo limitato tramite prompt testuali e possono incontrare difficoltà quando le istruzioni diventano troppo complesse. Inoltre, soffrono spesso del fenomeno di mode collapse, che riduce la varietà delle immagini generate.
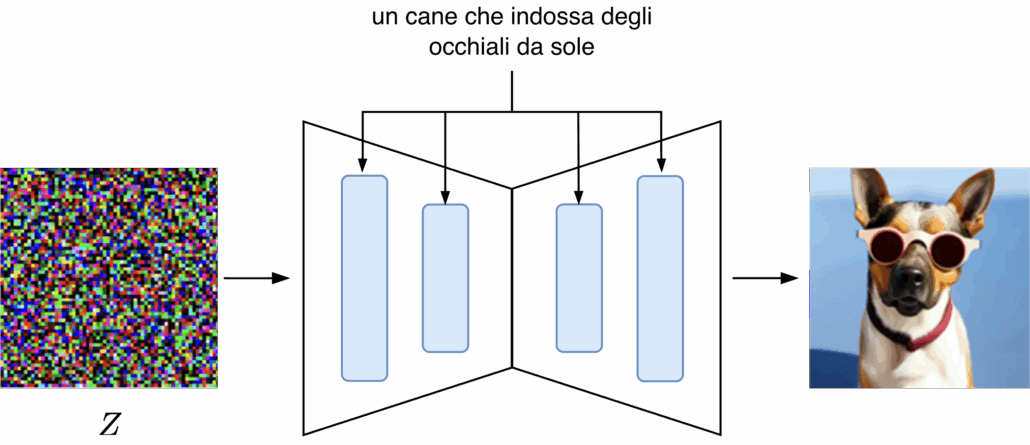
Modelli a Diffusione (Diffusion Models)
I modelli a diffusione generano immagini partendo dal rumore e rimuovendolo progressivamente attraverso una serie di passaggi successivi. Questi modelli eccellono nella produzione di immagini di altissima qualità, con grande coerenza visiva e capacità di seguire prompt complessi. Sono estremamente versatili e permettono un controllo fine grazie a tecniche come ControlNet e LoRA. Tuttavia, la generazione è più lenta rispetto ad altri approcci e richiede maggiore potenza computazionale.
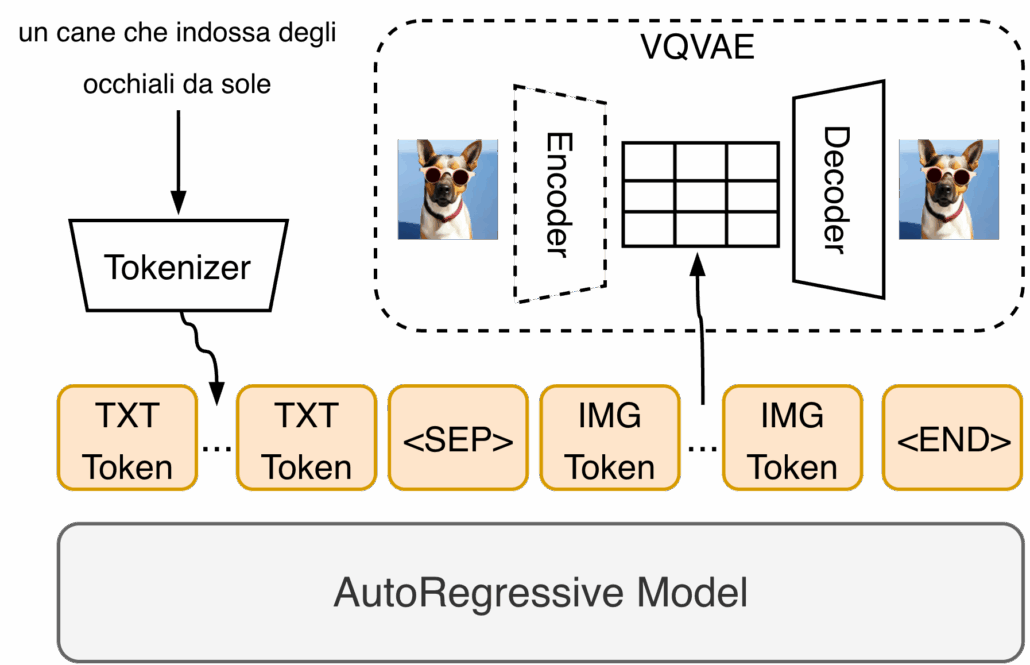
Modelli Autoregressivi (Autoregressive Models)
I modelli autoregressivi trasformano un’immagine in una sequenza di token visivi, generati uno dopo l’altro, proprio come un modello linguistico genera parole.
La loro forza principale risiede nella comprensione avanzata del linguaggio, che permette di interpretare e rappresentare scene complesse con elevata coerenza semantica. Tuttavia, la qualità del risultato può essere meno fotorealistica rispetto ai modelli a diffusione e dipende fortemente dalla qualità del vocabolario visivo utilizzato.
Text-To-image con cui sperimentare
https://gemini.google.com/app
https://app.leonardo.ai/
https://chatgpt.com/
https://stability.ai/
https://app.runwayml.com/
https://firefly.adobe.com/
https://chat.qwenlm.ai
Il prompt deve essere accurato (esempio)
Crea un'immagine in formato verticale per una conferenza 'IA e Magia' in Italia. L'immagine deve essere completamente priva di testo.
Tema delle città: Integra in modo discreto ma riconoscibile gli skyline o i monumenti emblematici delle seguenti sei città sullo sfondo o all'orizzonte: Torino, Genova, Milano, Bologna, San Marino, Roma. Le città devono essere rappresentate in uno stile unificato, possibilmente con riflessi luminosi su una superficie scura e acquatica.
Tema della magia (prestidigitazione): Rappresenta la magia con elementi di prestidigitazione classici e riconoscibili, senza alcuna connotazione esoterica, occulta o fantasiosa.
Utilizza carte da gioco Bicycle (dorso rosso o blu, facce standard) in movimento, che vorticano o fluttuano.
Utilizza dadi a sei facce classici (cubici, punti neri o colorati, senza cifre su più facce, né forme deformate). I dadi possono essere di diversi colori vivaci (rosso, verde, blu).
Possono essere presenti mani stilizzate e luminose (tipo particelle o digitali) che interagiscono con questi elementi, suggerendo la manipolazione magica.
Tema dell'IA (Intelligenza Artificiale): Rappresenta l'IA in modo creativo e futuristico. Evita grafici a istogrammi o circuiti stampati troppo letterali. Pensa piuttosto a:
Reti luminose complesse e interconnesse, ragnatele di energia, flussi di dati astratti.
Sfere di energia con sottili motivi tecnologici.
Elementi di IA che si intrecciano o interagiscono con gli elementi di magia.
Stile generale: Uno stile futuristico e onirico, con una dominante di colori blu profondi e accenti luminosi (neon, elettrici) per l'IA e le città. L'atmosfera deve essere moderna e intrigante.
Vincoli importanti:
NIENTE CAPPELLI A CILINDRO, BACCHETTE MAGICHE o altri cliché.
NIENTE CLICHÉ SULL'IA (robot caricaturali, codici binari che scorrono in modo troppo evidente).
TUTTI I DADI DEVONO ESSERE REGOLARI E CLASSICI.
NESSUN TESTO, DI NESSUN TIPO, SULL'IMMAGINE FINALE.




